
ZFS 设计思想简介
“ZFS: The last word in file systems”
本文是阅读了《The ZettaByte File System》 后所作的总结。
ZFS 最初由 Sun 公司为 Solaris 操作系统设计。主要设计思想是强数据一致性、管理便利性、持久可用性和高性能。ZFS 具有高度前瞻性而独树一帜的设计思想,被称为是“最终极的文件系统”。
如今的 ZFS 早已有了包括且不限于池化存储、快照、写时拷贝、Z磁盘阵列等特性。据鄙人的身边统计学而言受到 NAS 党的高度关注(另一个是经常被吐槽的 BtrFS)。
设计背景
在本世纪初,传统的本地文件系统虽然种类繁多,但是依旧存在诸多恼人的问题:
- 可靠性差
- 存在文件丢失问题
- 根目录挂了之后修复困难
- 莫名奇妙的数据损坏
- 错误配置破坏力强(比如在
/etc/fstab里误把hda0n0p0写成了hda1n0p0)
- 管理困难
- 一杯茶,一包烟,一个分区整一天
- 增加存储设备、变更文件系统存储容量困难
- 卷管理器不太像是人用的
- fsck 修复过慢
同时在 2002 年,当时的存储勃勃生机,万物竞发。稍有小钱的人家,阔绰地花上 2500 块的刀乐,便可拥有 2TB 的存储空间;而当时的文件系统设计还停留在那个 20MB 就是大款的八十年代。 由于激进的内存缓存策略,文件系统的性能瓶颈已经落到了数据写入上。
于是种种问题促使 Sun 公司的工程师们从头设计一种新式的文件系统,解决以上的问题。该文件系统应当有高度的数据完整性、简单方便的管理机制和非常高的容量。该文件系统针对 POSIX 标准设计,最终应当具有:
- 池化存储
- 写时拷贝
- 完整性强
- 基于对象
- 全新层次
- 保质期长
等特点。
设计理念及其实现机制
简单的管理机制
传统的文件系统管理缓慢、困难,误操作又容易造成大量数据损失,威胁系统管理员的数据、财产安全和身心健康。然而,由于这方面的操作在日常工作中较为罕见,这方面几乎没有专家。
然而随着越来越多的人使用计算机系统,他们也事实上(主动或被迫地)成为了系统管理员。在这个时候就不能指望人人精通这方面的工作了。
ZFS 的实现团队认为,磁盘管理的任务可以高度地简化和自动化,界面也应该高度友好。管理员应当能随心所欲地增减存储设备而不费心在 mount/umount 上。总之,管理磁盘应当是一项简单、迅捷而不易出错的工作。
ZFS 将令用户专注于实现目的而非繁琐的磁盘操作细节上。由于将文件系统作为管理单元,在之前的文件系统上头使用更多的自动化抽象层比如加一个GUI其实意义不大。将各类细节隐藏在文件系统的更高级抽象层次中也解决不了许多高级问题。
池化存储
虚拟存储器是计算机体系结构的革命性创造。在内存管理方面,用户从来不用费心费力要给每个程序、内核分配多少空间,自己去手动对每个内存条调用 mount/umount,然后 format 成某种特定的形式。
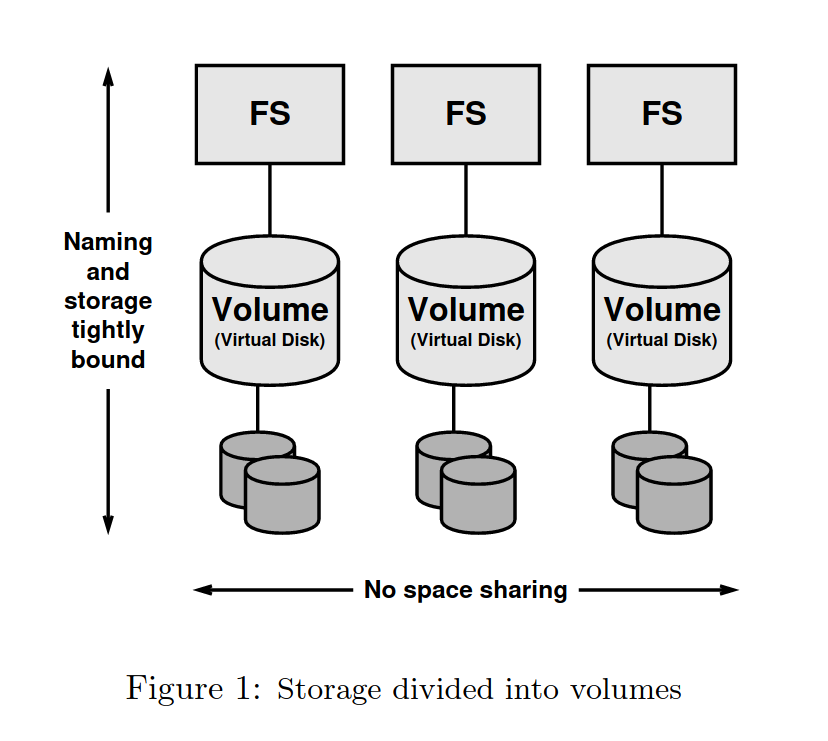
文件系统虽然已经做了抽象,但是不够彻底,归根到底还是局限于几个逻辑设备——不论从逻辑上还是物理上,对用户似乎没有太大区别。
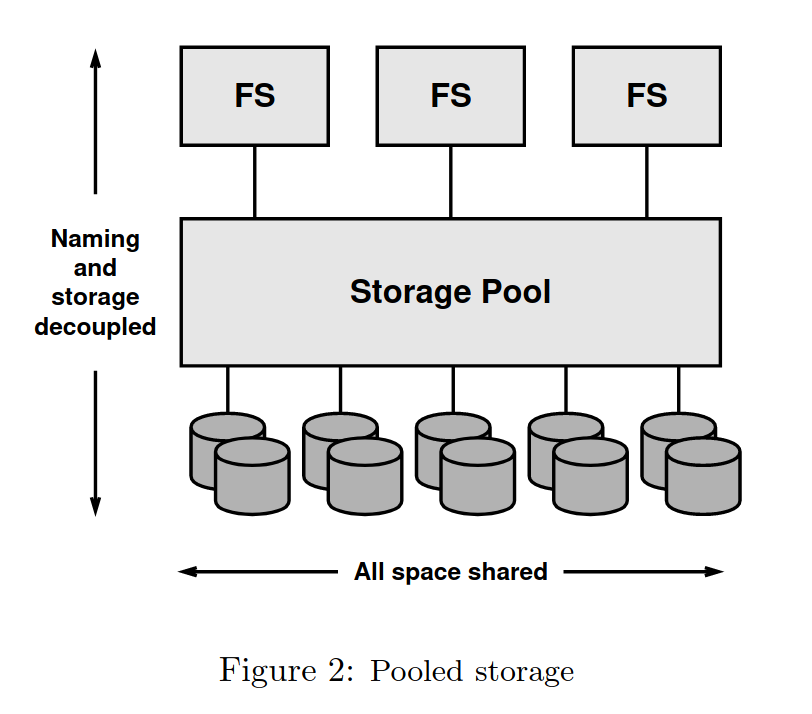
作者认为,文件系统应当如虚拟内存与实际的内存地址解耦一般同具体的硬盘设备解耦。多个文件系统可以在同一个虚拟化的池化空间上工作。存储空间分配的任务应当同文件系统自身解耦,转交给更下层的“分配器”中去。
可变的文件系统大小
传统的文件系统使用起来需要手动、静态地指定文件系统的最大大小,而某些文件系统虽然具有自动化工具,却需要手动运行,速度慢,只能在特定情形下正常工作,并需要真正具有改变体积功能的逻辑卷的支持。
如此的文件系统可能还存在“内部碎片”的问题——即使大量的磁盘空间并没有使用,但是只要被分区表指定给一个文件系统之后就无法为其他文件系统所用。这个问题其实并不被大伙所关心——比起跟文件系统配置对线,浪费存储空间似乎就没啥大不了的——当时的存储空间就已经越来越便宜了。
除却随着插入和移除设备改变文件系统大小之外,能不能更进一步,随着写入、删除数据改变文件系统大小呢?当然,这个过程应当是高度自动化的。
始终的一致性
当时的文件系统仍然允许盘上数据在某些不同的时间段时保持不一致——显然如果中途系统崩溃或者掉电了那就一硬盘锟斤拷了,只能在下次启动之前修理。
不同的文件系统有不同的修理方法:
- FFS 基于
fsck进行修复; - 元数据日志式文件系统将写入的元数据的“重放”实现一致性;
- 软更新文件系统会留下泄露的数据块与信息节点;
- 结构化日志式文件系统通过一个个具有完整性的检查点保证完整性——但是过于频繁地构建检查点有很大的性能问题。
在启动后再进行修复几乎是不可接受的。在启动器(bootloader) 需要在文件系统有一定的一致性之后才能从根文件中找到操作系统的情形下,就要求启动器自己就几乎集成一套修复的程序——太大了。
要想一劳永逸地解决这些问题,最好的办法是让磁盘上的数据永远保持一致。在这方面做得最好的是 WAFL 文件系统。为了实现这种功能就需要一种简单的算法可以令文件系统可以迅速在保持完整性的状态之间切换。
高存储容量
早期的文件系统寻址是 32 位块寻址的,最多支持到数 TB ——但是前文已经说在当年只要有 $2500 就能达到 2TB 的容量,显而易见 32 位已经是日薄西山。但是 64 位就能稳坐江山了?在那个勃勃生机的时代,几乎每 9~12 个月存储空间就能翻倍——如此看来 64 位存储空间达到极限也就那么十几年的事情。
为了延长文件系统的保质期,ZFS 实现团队决定使用 128 位的块寻址方式——那比 32 位高到不知道哪里去了。
当然,有了这么高的存储容量,诸如可扩展的目录查找算法、元数据分配、块分配、IO调度等配套设施也是很重要的!
如此大的存储容量,万一出了差错,还是要负起责任的。类似 fsck 的工具,修复文件系统的复杂度是线性时间复杂度的,这在如此大容量的存储上依然是难以承受的。
错误检测与修复
在现实世界中,磁盘、磁盘阵列等存储设备往往会出各种各样的Bug,读错误、写错误、幻读等层出不穷;文件系统自身也可能暗含各种各样的Bug,其他软件或者系统管理员的状态也不是完全可信的。如果在数据块层面即可对收到的数据进行验证,也只能解决小部分的文件系统错误。
ZFS 会对所有读到的数据进行校验,如此即可预防相当多的文件系统问题(当然这也只能解决一小部分问题)。同时也会将矫正过的数据写回到磁盘中。
卷管理器集成
传统的卷管理器通过在逻辑上模拟一个物理块设备,以实现例如磁盘镜像的功能。通过这种方式可以方便快捷的支持几乎所有的文件系统而不用修改文件系统代码。但是在逻辑上模拟物理块设备无法获得语义化的文件系统信息如数据块的依赖关系,也无从得知哪些数据块已经分配以至于只能假设所有文件块都已经分配。在这种情况下保证数据一致性是非常困难的。
许多的文件系统都有了自己的卷管理器。但是如果能将文件系统和卷管理器间的接口稍作修改,而非简单的块设备接口,显然可以在足够轻量化的情况下获得高读写性能。
高存储性能
ZFS 的存储性能应当是非常高的。为了达到这一点 ZFS 将重新设计并克服数十年来传统接口的桎梏。前文已经说过,在激进的缓存策略下写性能才是更重要的。因此,ZFS将通过如令块分配策略更倾向于写操作(也许可以类比 RwLock 的倾向性?)、批量化细微写入操作为大的连续写入操作来提高性能。
总结
通过本文可以看到,ZFS 的设计理念是非常超前的。提出了许多独树一帜的思考,针对了多个文件系统存在的缺陷进行设计。
不知不觉将写了这么多,感觉有点细琐了。在下篇文章中,笔者将阐述 ZFS 的具体架构。